
Data Stream 서비스 소개

네이버클라우드에 데이터 스트림이라는 서비스가 새롭게 등장했습니다.
이 서비스의 가장 큰 특징은 '서버리스' 입니다. 내가 별도의 서버를 만들지 않아도, 내부적인 서버가 존재하고 있어서 바로 동작한다고 생각하면 편합니다.
정리하면, Data Stream은 서버리스 Kafka 도구라고 이해하면 되겠습니다.
사용 방법도 매우 간단합니다.
Data Stream 서비스 활용

0. 대시보드 확인
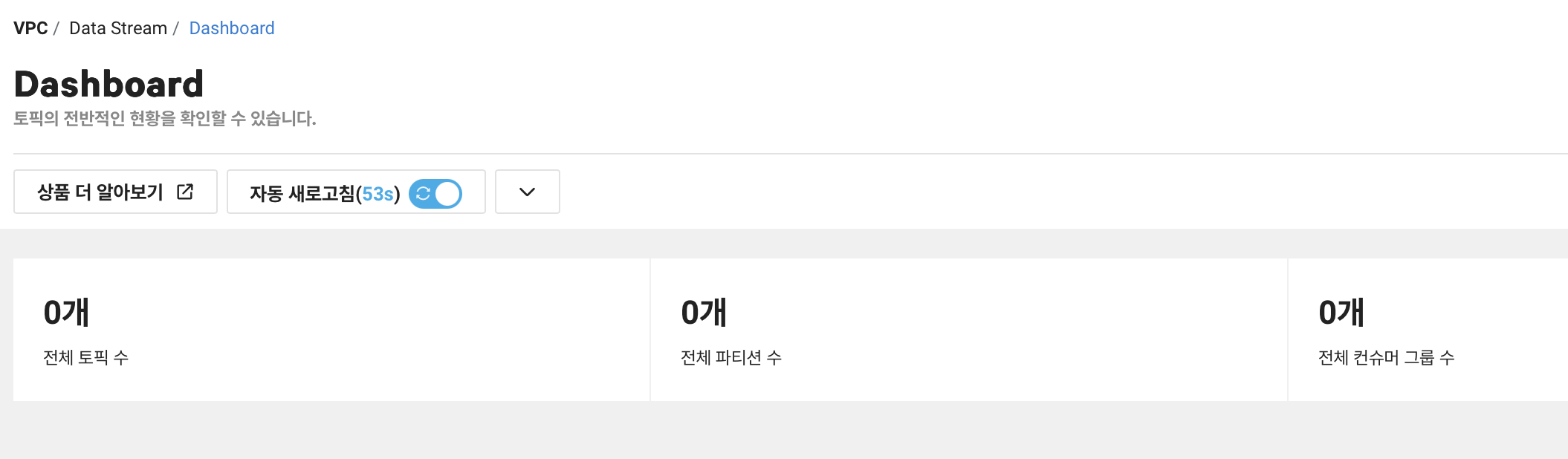
Data Stream 서비스는 별도 신청과정이 없습니다. 토픽을 생성하기 전에는 요금 부과도 되지 않고, 위처럼 대시보드에서 토픽, 파티션, 컨슈머 그룹 수가 0개인 것을 한눈에 확인할 수 있습니다.
사전 준비사항으로, 서브 계정을 만들고, 인증키를 받아두어야 합니다.
서브 계정 (Sub Account)
이 상품(Data Stream)은 메인 계정으로는 토픽에 접근할 수 없게 막아놓았습니다. 그래서 서브 계정을 반드시 만들고, 적절한 권한과 인증키 부여를 해야 작동합니다. 추가로 서브 계정은 무료입니다.
서브 계정에 인증키 부여와 권한을 부여하려면, 메인 계정으로 접근하는 게 가장 편합니다.
VPC > Sub Account > Sub Accounts로 접근해서, "서브 계정 생성"을 진행합니다. 테스트 용으로 만들고, "콘솔 접근" 허용을 해야 합니다. 또한, 보안이 필요하다면, 지정된 IP 대역을 설정해주시면 더 안전하게 활용할 수 있습니다.
대신, 지정한 장소 외 다른 곳에서 서브 계정으로 소스 접근이 안될 수도 있습니다. 테스트할 때는 모든 곳에서 접근 가능하도록 설정하고, 테스트가 성공한 뒤에 변경하는 것을 추천합니다.
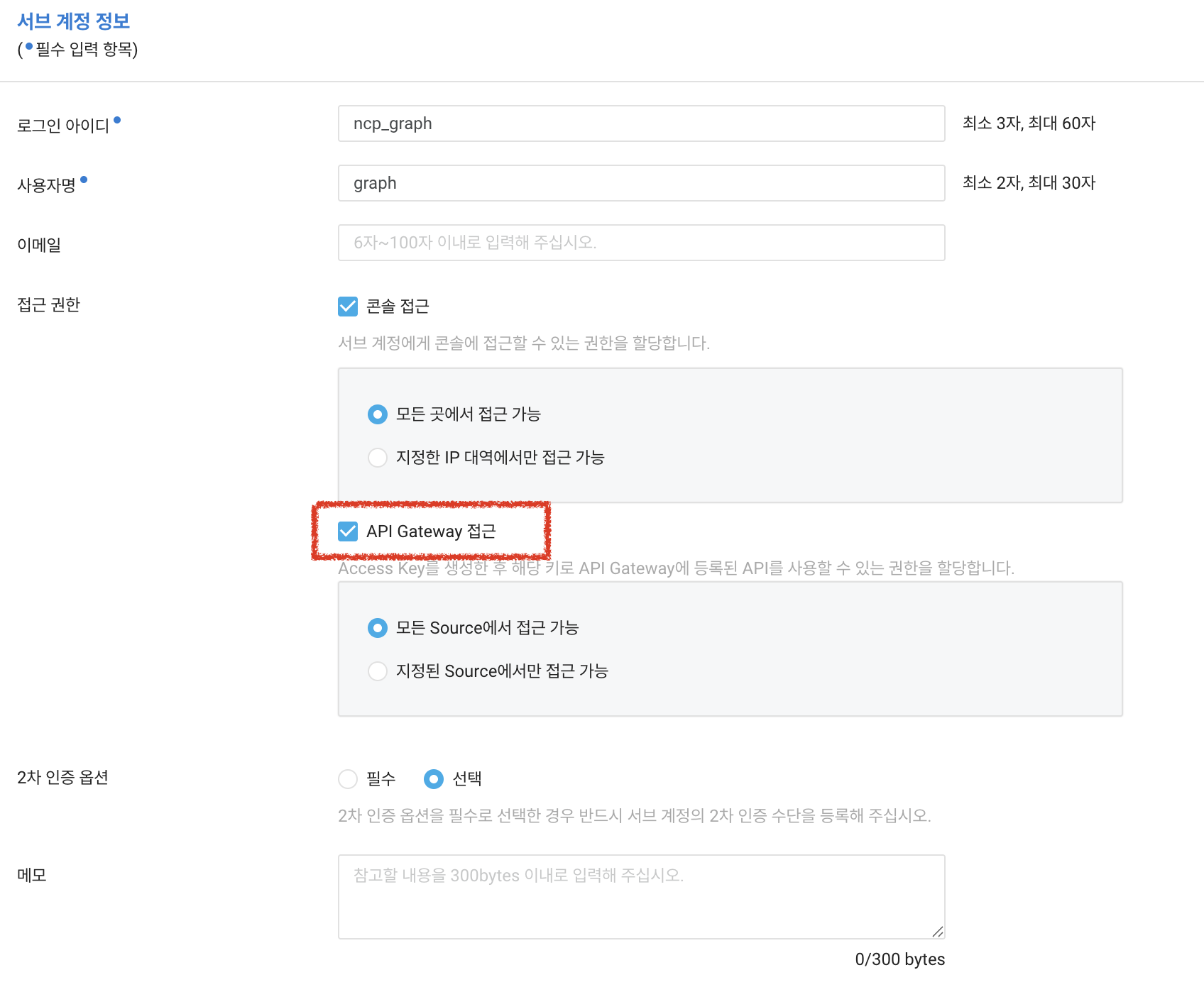
위 콘솔 접근과 같은 방식으로, API Gateway 접근도 체크해야만 서브 계정에서 인증키 정보를 만들고, 이를 가져올 수 있습니다. 꼭 선택해주세요.

권한 부여
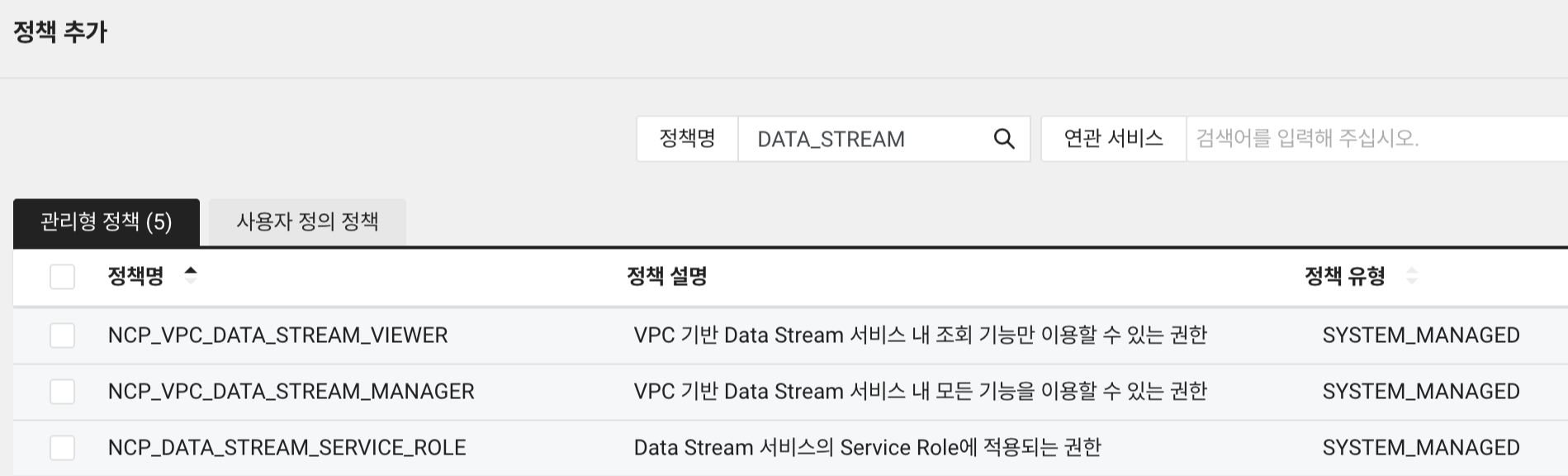
생성 완료 후, 해당 서브 계정에 권한을 부여해줍니다. 권한은 DATA_STREAM으로 검색해서 나오는 것을 테스트용으로 적용해두겠습니다. 권한 부여는 다음과 같이 진행합니다.
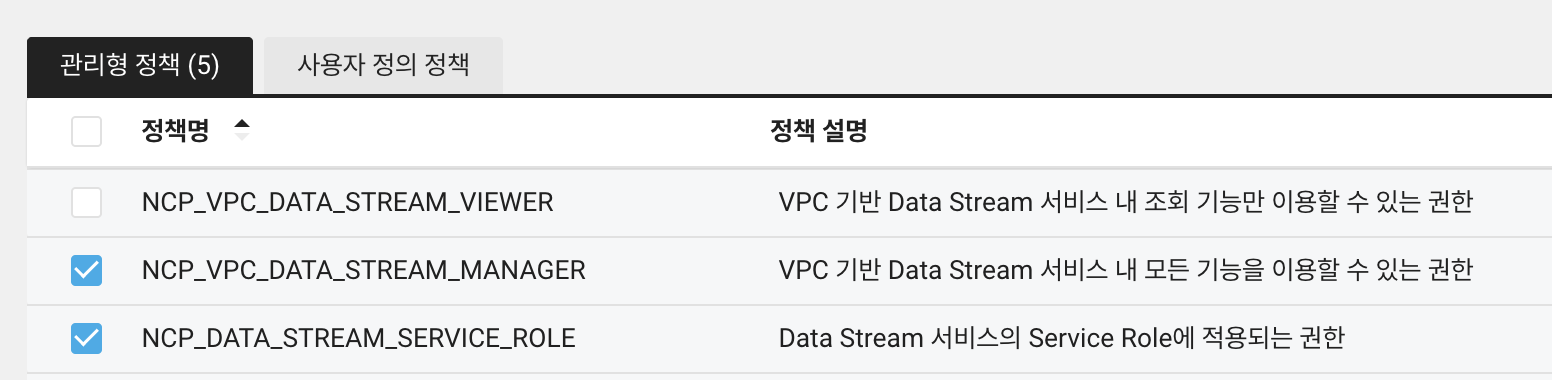
먼저 정책 추가를 누르고, 관리형 정책에서정책명으로 DATA_STREAM을 입력하면 나오는 아래 세가지 정책이 있습니다. 이 중에서 VIEWER를 제외하고 모두 선택해줍니다.
인증키 정보
다음으로, 인증키 정보를 가져오겠습니다. Access Key 탭에서 추가를 눌러줍니다. 해당 서브 계정의 인증키 정보가 나오는데, Access Key id, Secret Key 정보를 메모해두세요.
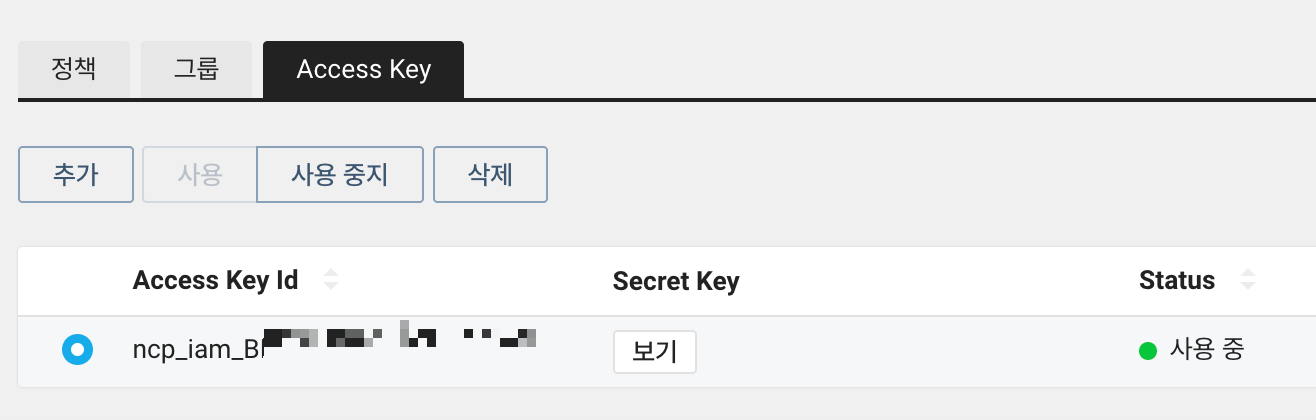
참고로, Secret Key는 '보기' 버튼을 누르면 확인할 수 있습니다.
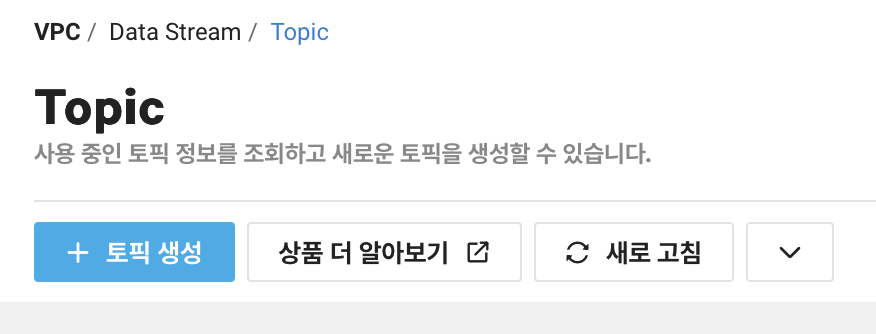
토픽 생성
서브 계정으로 접속하면, 콘솔에서 서비스를 눌렀을 때, 다음과 같은 화면이 화면이 나타납니다.
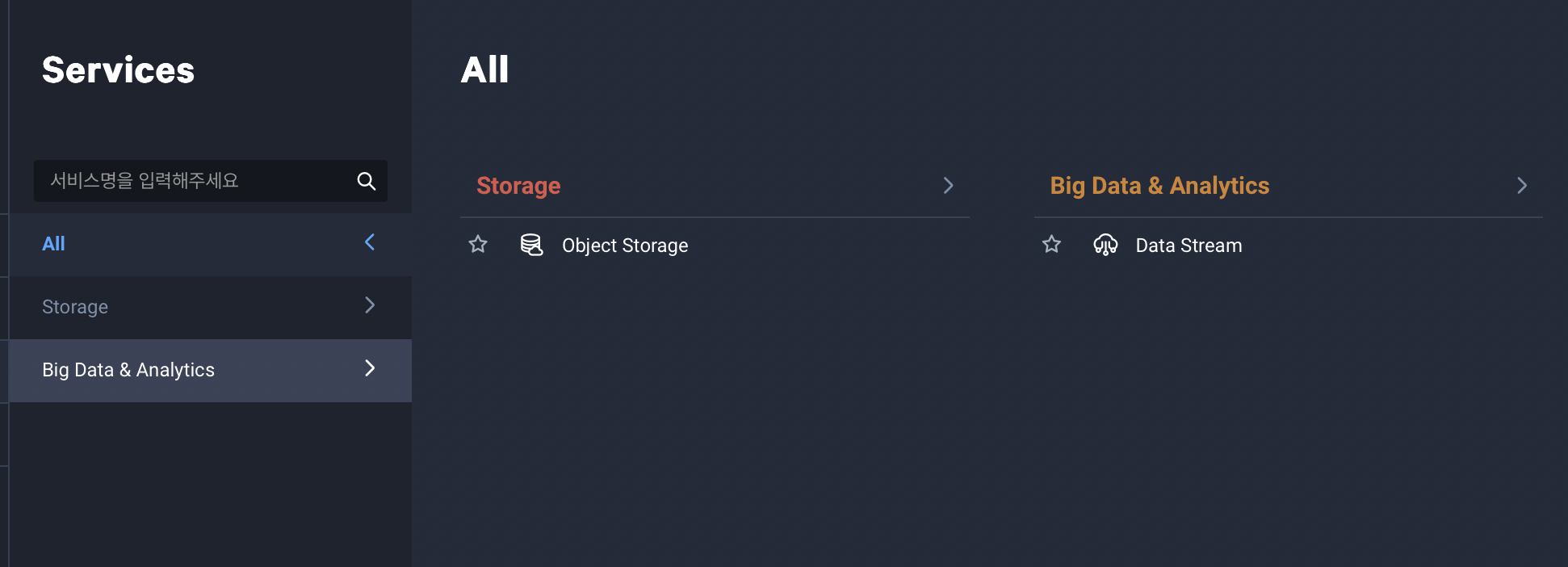
위에서 권한을 부여한 것과 관련된 상품만 선택할 수 있습니다. Data Stream을 누릅니다.
이제 토픽을 생성하면 바로 사용할 수 있습니다. 주의할 점은, 토픽 생성과 동시에 분당 요금이 부과됩니다.
토픽 생성을 누릅니다. 이름은 임의로 graph 라고 지었습니다.
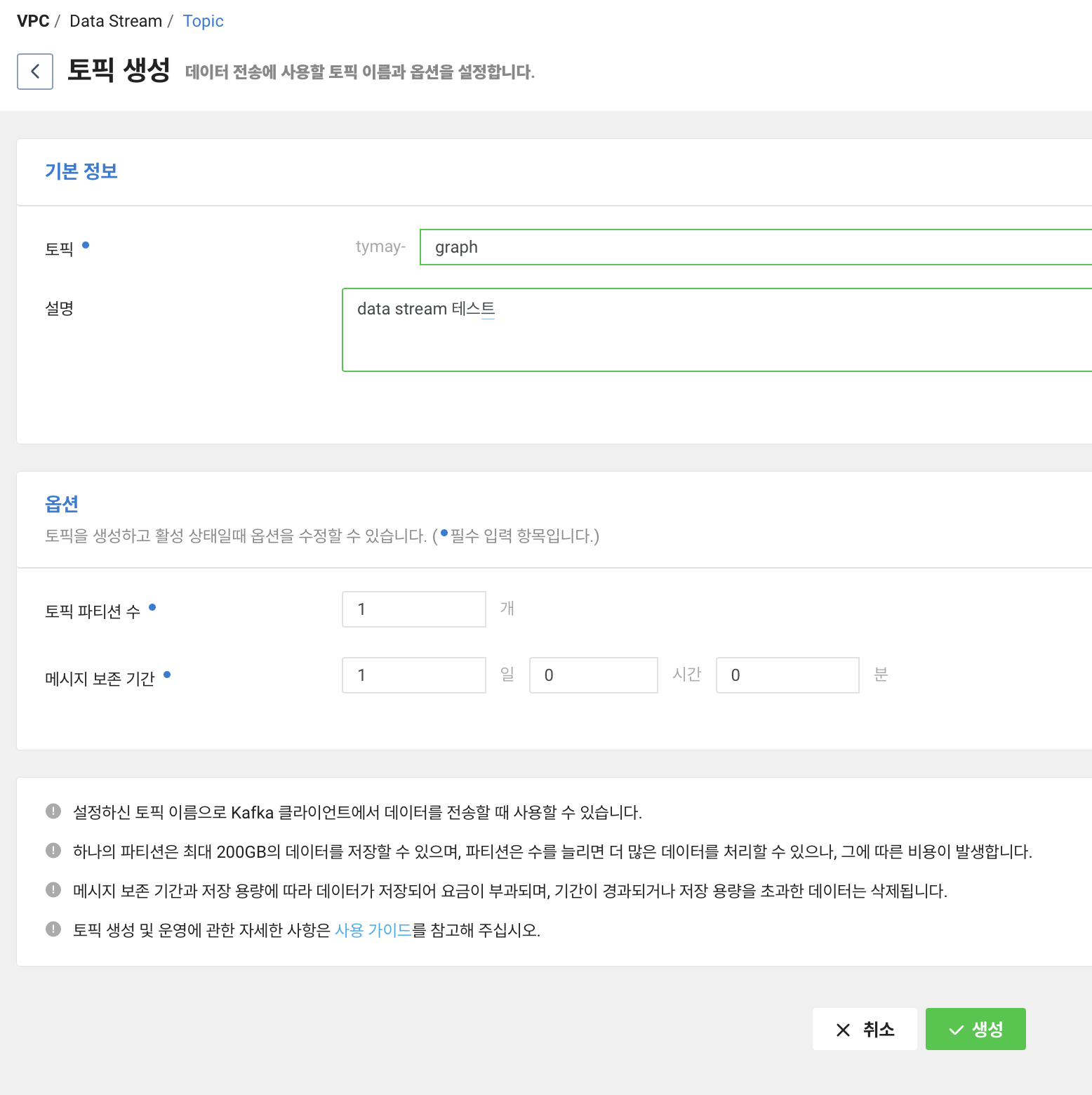
여기서 주의할 점은 토픽 이름에는 특수문자 하이픈(-)만 허용이 되고, 최대 200자만 입력할 수 있다는 것입니다.

토픽이 생성 완료되면, 아래 토픽 이름, 파티션 개수, 보존 기간 등이 적혀있습니다. 파티션 개수는 위에서 지정한 개수로 나오고, 수정할 때는 파티션 수를 증가하는 것만 가능하고, 파티션 수를 줄이는 건 불가능하다는 점을 유념해두세요!
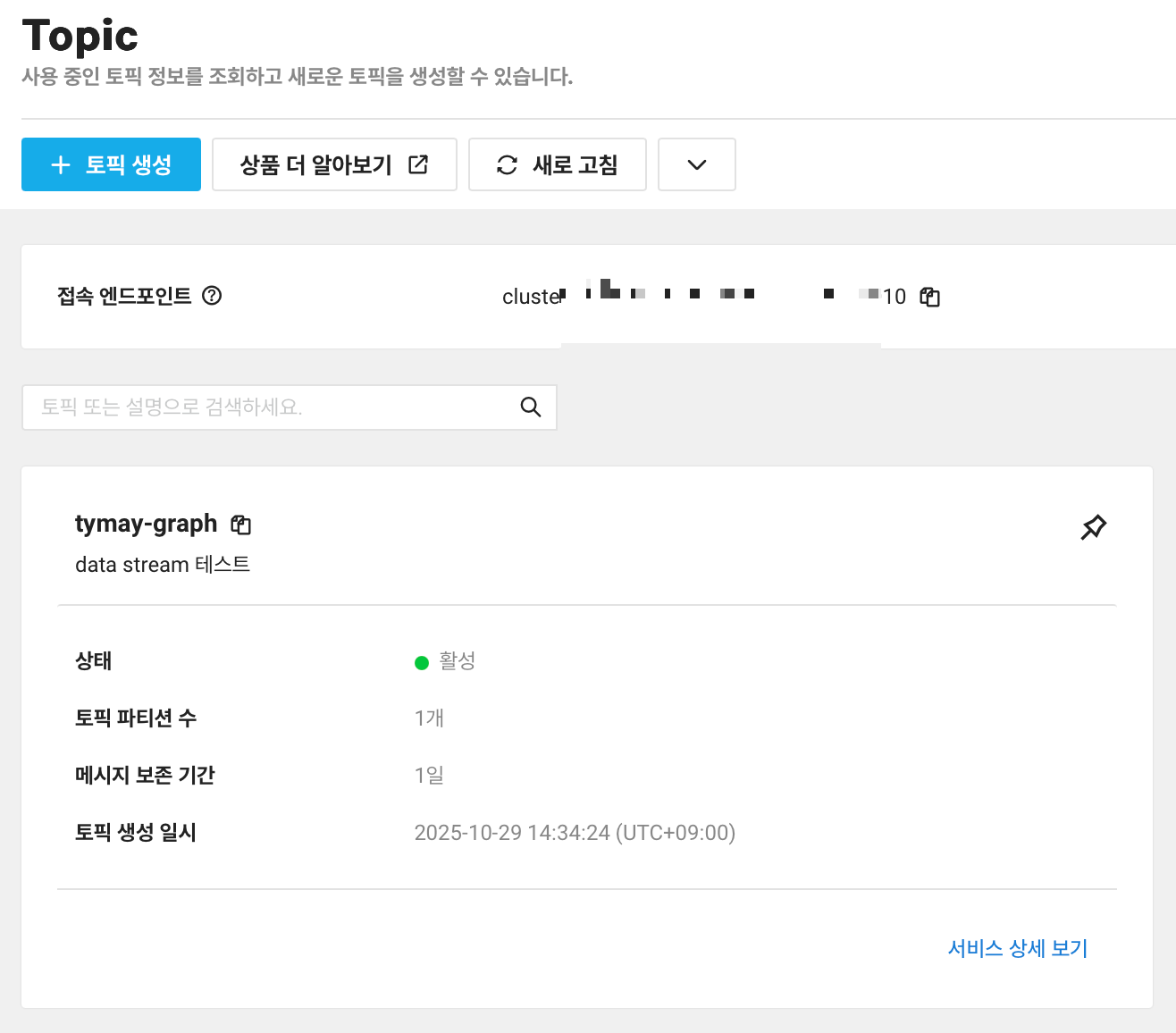
접속 엔드포인트는 여러번 생성해보니 대부분 비슷하게 나옵니다.
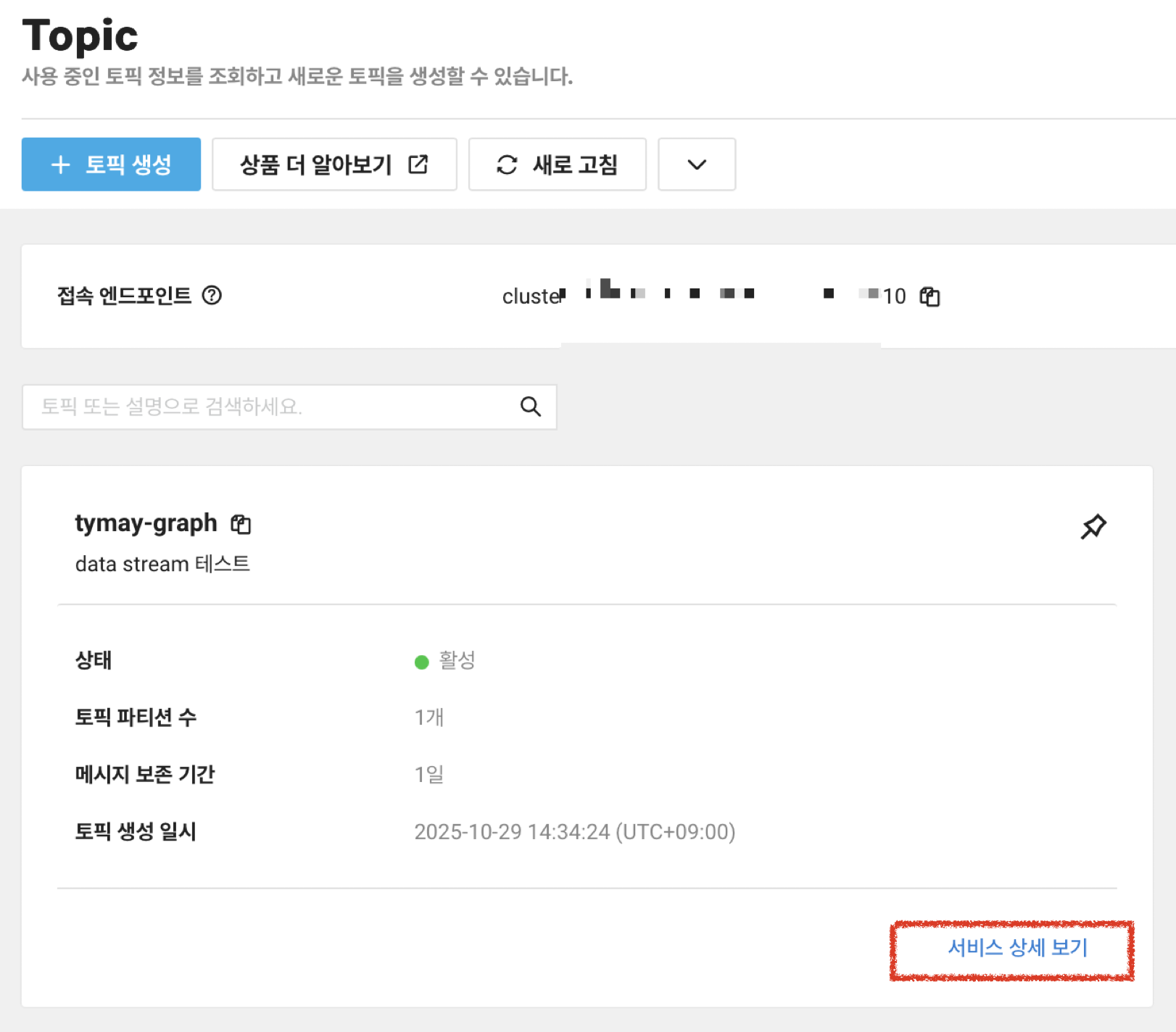
토픽 이름, 접속 엔드포인트를 복사해둡니다. 참고로 제 토픽 이름은, tymay-graph 네요.
우측 하단 서비스 상세 보기를 누르고, 데이터 탭 > 파티션 0을 선택하면, 아래와 같이 아직 전송된 데이터가 없는 것을 확인할 수 있습니다.
Producer 테스트
Producer는, Kafka 클라이언트로 메시지를 토픽에 전송하는 방법입니다. 서버리스의 강점이 바로 여기에 있습니다. 모든 인프라가 내장되어 있으니, 제공된 엔드포인트 주소, 토픽 이름, 인증키 정보만 입력하면 바로 이 TCP 엔드포인트를 통해 메시지 전송이 가능합니다.
사전에 필요한 파이썬 라이브러리 kafka-python을 설치합니다.
pip install kafka-python
네이버클라우드 가이드에서 제공한 Python 코드는 다음과 같습니다. 여기서 topic_name은 기재된 대로 tymay-graph로 적었습니다. 본인이 지정한 이름으로 수정해서 topic_name을 입력해주세요. 이 코드는 data_stream.py 라는 파일로 저장합니다.
import ssl
from kafka import KafkaProducer
import json
brokers = "cluster로 시작하는 엔드포인트 주소"
topic_name = "tymay-graph" # 각자 만든 토픽 이름으로 수정
username = "ncp_iam_으로 시작하는 서브계정 AccessKey"
password = "ncp_iam_으로 시작하는 서브계정 SecretKey"
security_protocol = 'SASL_SSL'
sasl_mechanism = 'PLAIN'
# Create a new context using system defaults, disable all but TLS1.2
context = ssl.create_default_context()
context.options &= ssl.OP_NO_TLSv1
context.options &= ssl.OP_NO_TLSv1_1
producer = KafkaProducer(bootstrap_servers = brokers,
sasl_plain_username = username,
sasl_plain_password = password,
security_protocol = security_protocol,
ssl_context = context,
sasl_mechanism = sasl_mechanism,
api_version = (0,10),
retries=5)
partition = 0
key = "key-1"
value_dict = {'key': key, 'data': "Hello, Kafka!"}
msg_value_json = json.dumps(value_dict)
producer.send(topic=topic_name,
key=bytes(key, 'utf-8'),
value=msg_value_json.encode("utf-8"),
partition=partition)
producer.flush()
위 파이썬 코드 파일을 실행합니다.

정상적으로 실행되면, 다음 줄에는 아무것도 뜨지 않아야합니다. 무소식이 희소식이에요.
이제 콘솔에서 확인해보겠습니다. "Hello, Kafka!" 메시지를 확인해야 합니다.
Producer 결과 확인
참고로, 한글로 값을 넣으면 아래처럼 다른 값으로 출력됩니다. 유의해주세요!
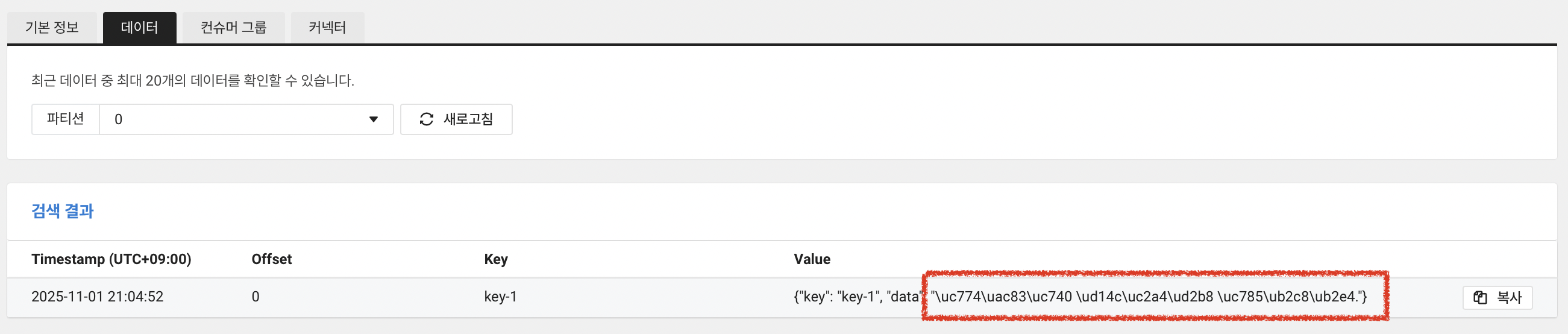
다시 확인해보겠습니다.
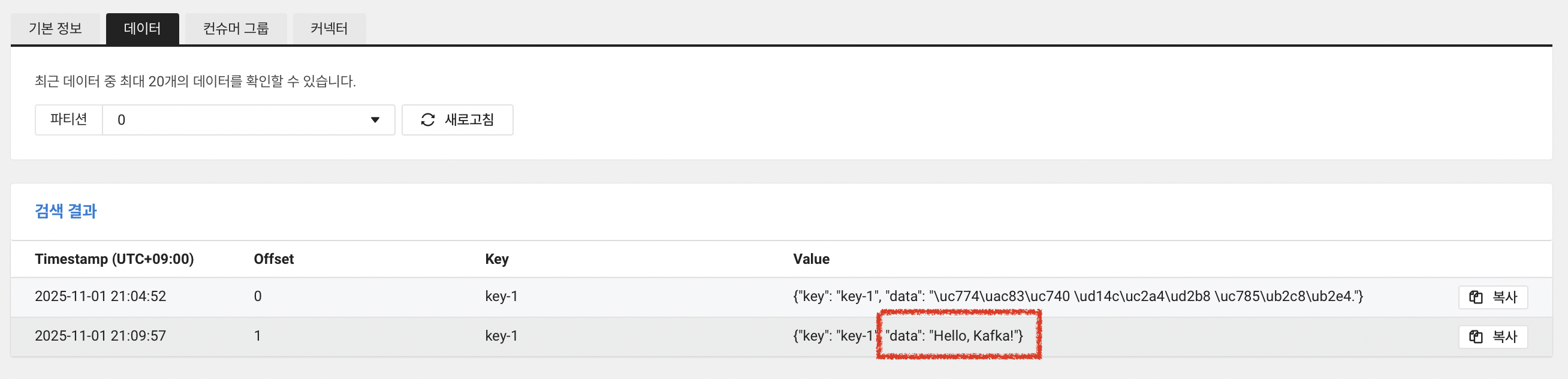
성공이네요!
"Hello, Kafka!" 메시지를 바로 확인할 수 있습니다. 이렇게 서버리스로, 이미 구축된 내장된 서버에서 작동하므로 아주 간단하게 데이터 스트리밍 기능을 수행할 수 있습니다.
이제 Python기반 Kafka 클라이언트 애플리케이션을 사용하여 Data Stream 서비스에 접속해보고, 메시지를 토픽에 송신했습니다. 메시지를 전달했다고 표현해보겠습니다.
Consumer
다음에서는 Consumer 기능을 사용해, 제공된 TCP 엔드포인트에서 메시지를 꺼내서 출력해보겠습니다. Kafka client는 이미 설치된 것으로 가정하고, 다음 Python 코드를 data_stream_consumer.py로 저장해줍니다.
import ssl
from kafka import KafkaConsumer
brokers = "cluster로 시작하는 엔드포인트 주소"
topic_name = "tymay-graph" # 각자 만든 토픽 이름으로 수정
username = "ncp_iam_으로 시작하는 서브계정 AccessKey"
password = "ncp_iam_으로 시작하는 서브계정 SecretKey"
security_protocol = 'SASL_SSL'
sasl_mechanism = 'PLAIN'
# Create a new context using system defaults, disable all but TLS1.2
context = ssl.create_default_context()
context.options &= ssl.OP_NO_TLSv1
context.options &= ssl.OP_NO_TLSv1_1
consumer = KafkaConsumer(topic_name, bootstrap_servers = brokers,
group_id = "test-consumer-group", # 원하는 컨슈머그룹 이름 지정
auto_offset_reset='earliest',
sasl_plain_username = username,
sasl_plain_password = password,
security_protocol = security_protocol,
ssl_context = context,
sasl_mechanism = sasl_mechanism)
from datetime import datetime
for message in consumer:
print(f'({datetime.now()}) Topic : {message.topic}, Partition : {message.partition}, \
Offset : {message.offset}, Key : {message.key}, value : {message.value}')
실행하게 되면, 다음과 같이 입력한 메시지 혹은 데이터가 출력됩니다. "Hello, Kafka!" 메시지를 찾았습니다.

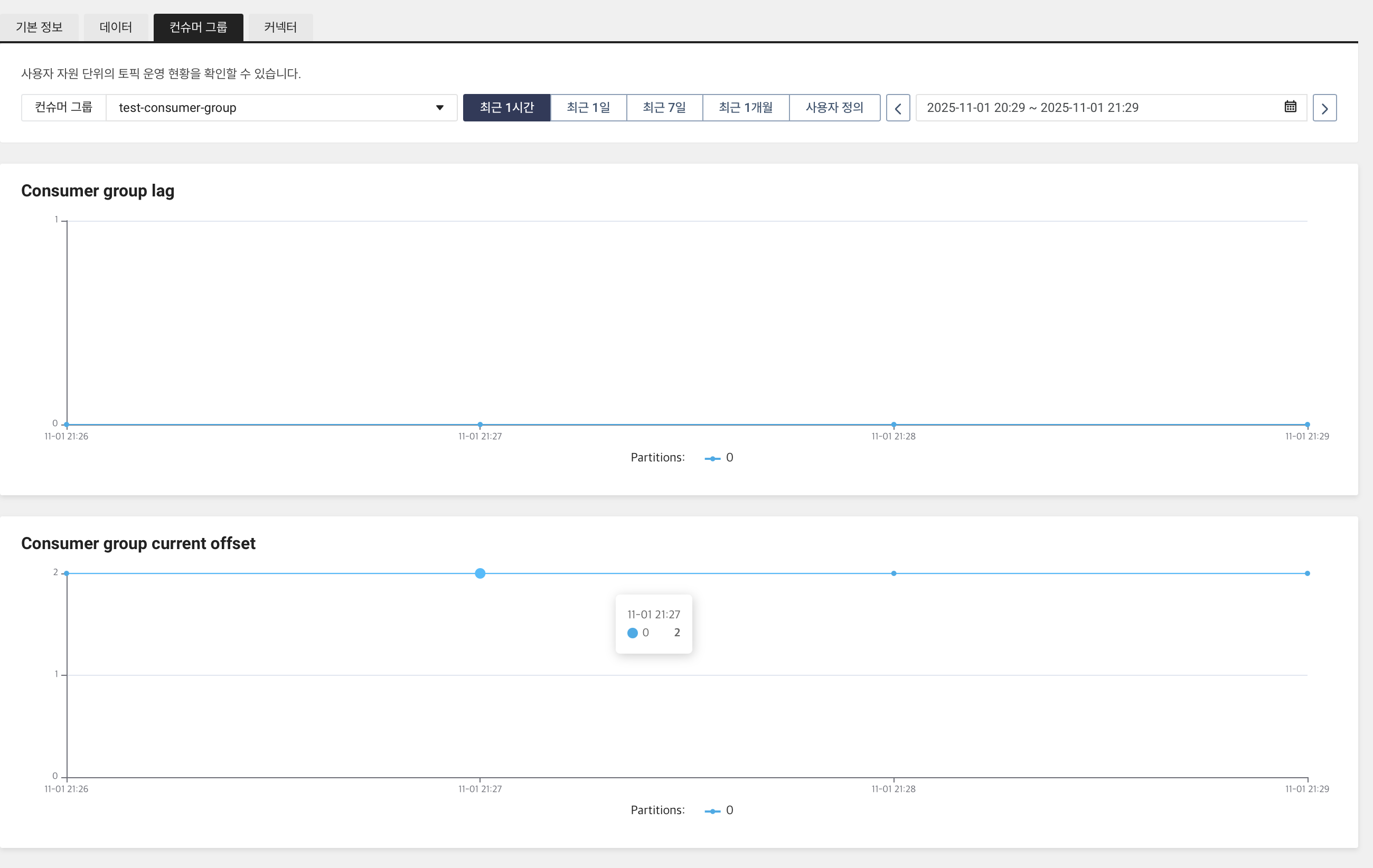
또한, 콘솔에서는 아래와 같은 빈 화면에서, test-consumer-group 이름으로 된 컨슈머 그룹이 생성되며, 오프셋 개수를 시각적으로 확인할 수 있습니다. 현재 2개가 있다고 표기합니다.
주의 사항

처음 실행할 때, test-consumer-group에서 한번 메시지를 읽고나면, 동일한 코드를 실행했을 때 메시지가 출력되지 않습니다. 이 group_id가 일종의 책갈피가 되며, 이것이 마지막으로 가있는 상태로, 다시 읽지 않습니다.
참고로, auto_offset_reset='earliest' 설정은 "이 그룹이 처음 접속해서 책갈피가 아예 없을 때만 처음(earliest)부터 읽어라"라는 뜻입니다. 여기서 한번 읽었다면, 책갈피가 있으니 이 설정은 무시됩니다.
다시 읽어서 출력을 시키려면, group_id를 None으로 설정해서 실행합니다.
consumer = KafkaConsumer(topic_name, bootstrap_servers = brokers,
group_id = None,
auto_offset_reset='earliest',
...
)
한번 실행하고, ctrl+c 를 눌러서 실행을 종료합니다. 그 뒤에 다시 실행해도 메시지가 잘 출력되는 것을 확인할 수 있습니다.
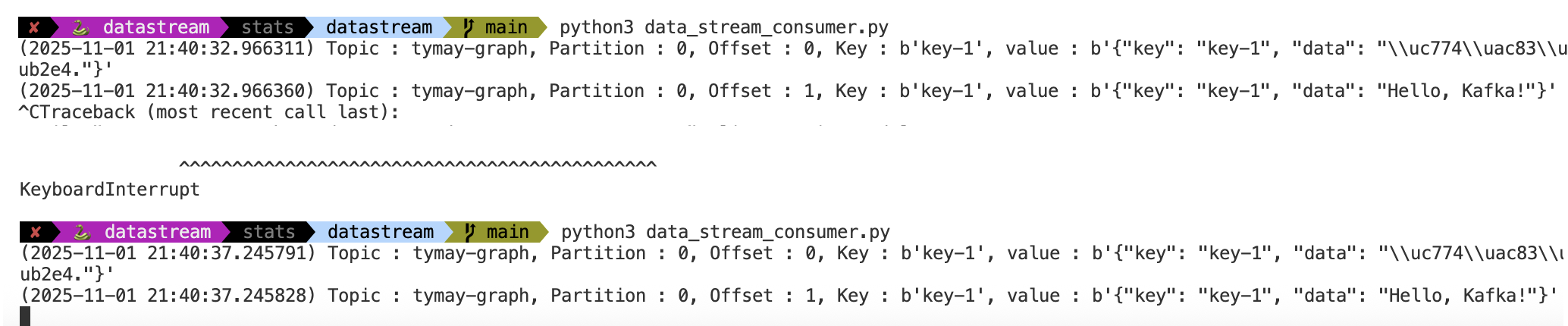
이제 다시 group_id를 test_consumer_group으로 설정하고 실행합니다.

이렇게 실행 중인 상태에서, producer 코드를 실행해서 메시지를 토픽에 새롭게 전송해보겠습니다. 새로운 터미널로 조작해볼게요.
처음에 만든 data_stream.py 파일에서 아래 'data' 값만 "Hello, DataStream!" 으로 수정합니다.
value_dict = {'key': key, 'data': "Hello, DataStream!"}
이제 data_stream.py 파일을 실행합니다. 이후, "Hello, DataStream1!", "Hello, DataStream2!"로 수정해서 여러번 실행해주었습니다.
그 결과, 아래 그림처럼 우측 터미널(Producer)에서 실시간으로 전송한 토픽 메시지를 좌측 터미널(Consumer)에서 확인해서 출력하는 것을 확인할 수 있습니다.

이제 콘솔 > 데이터 탭에서 실제 토픽으로 전송된 메시지를 확인합니다.
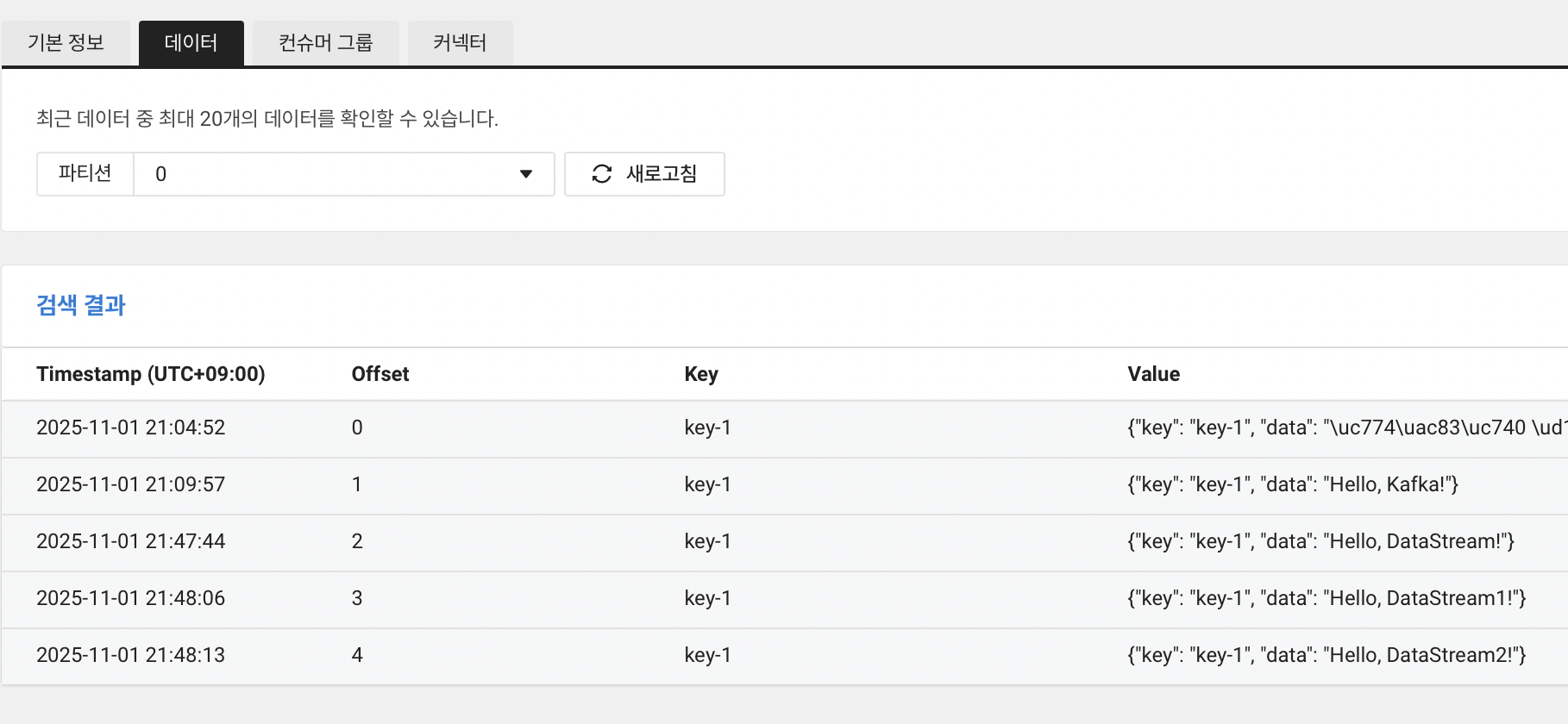
다음으로 콘솔 > 컨슈머 그룹 탭에서는, 현재 오프셋도 2개(0,1)에서 5개(0,1,2,3,4)로 증가한 것을 시각적으로 확인할 수 있습니다.
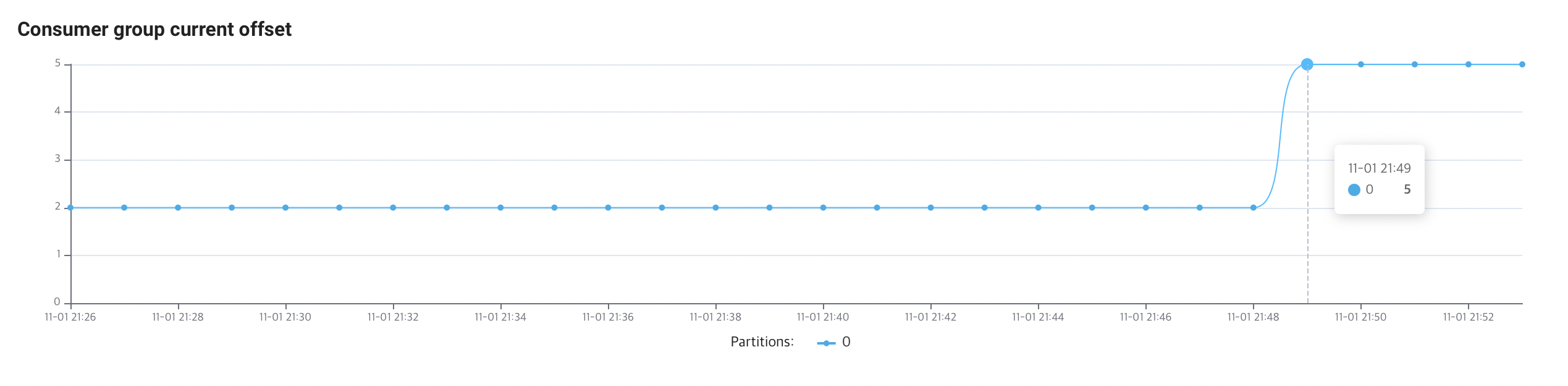
이렇게 별도의 서버 없이도 DataStream 서비스를 활용해서, 실시간으로 토픽에 메시지를 전송하고, 전송된 메시지를 꺼내어 확인해보는 과정을 수행했습니다.
다음 글에서는 기존 Cloud Data Streaming Service(CDSS)라는 상품과 이 DataStream 상품의 기능을 간단히 비교해보겠습니다.
읽어주셔서 감사합니다.


'네이버클라우드' 카테고리의 다른 글
| 네이버클라우드 서버와 VSCODE 연동: Python (0) | 2025.01.07 |
|---|---|
| [Ncloud] MinIO 다중 노드 다중 저장소(MNMD) (3) (0) | 2024.09.30 |
| [Ncloud] MinIO 단일 노드 다중 저장소(SNMD) (2) (0) | 2024.09.23 |
| [Ncloud] MinIO를 싱글노드로 구성하기(1) (1) | 2024.09.20 |
| NAVER Cloud Platform Certified Artificial Intelligence (NCAI) 후기 및 조언 (3) | 2024.02.24 |